[論文筆記] DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation
論文資訊
前言
今天要介紹的論文是DAFormer,個人認為這是一篇Unsupervised Domain Adaptation (UDA)領域很重要的論文。在這篇論文之前,幾乎所有論文都是採用卷積神經網路,而這篇論文首次在UDA領域中使用Transformer架構。
DAFormer發表於CVPR 2022,作者為Lukas Hoyer。近期有很多篇Unsupervised Domain Adaptation (UDA)領域的SOTA都是他發的,而且都有提供可以還原論文數據的開源程式碼。個人認為他的論文可信度很高,非常推薦大家閱讀他的論文!
其實在閱讀這篇論文之前,我也曾經想過「反正Transformer在很多情況下本來就比卷積神經網路厲害,那這樣單純在UDA領域中引入Transformer增加mIoU真的有什麼好說嘴的嗎?」。但看完這篇論文後,才發現原來我錯了,他想的其實比我本來還多,並且深深覺得作者很厲害。至於我覺得厲害的點在哪裡,就讓我們慢慢往下看吧~
論文方法
本篇論文主要有以下幾點貢獻,本章節將會依序介紹各個部分:
- 將Transformer架構引入UDA方法中
- Rare Class Sampling (RCS)
- Thing-Class ImageNet Feature Distance (FD)

1. 為什麼Transformer適合用於UDA中?
雖然Transformer跟Convolution在運作時都會去計算Weighted-sum,但他們對於已訓練模型權重的方式還是不太一樣:
- Convolution的權重在訓練結束時就固定了。
- Transformer的Self-attention機制卻可以在Inference時,動態地依據當下的輸入資料的相似性來產生對應的Affinity-map,再依據得到的Affinity-map做出預測。
基於上述原因,比起Convolution,Transformer能產生更General的預測結果,減少Domain-shift造成的影響。
🤓:另外,我自己覺得有可能是不同Domain的影像中,各個類別物體以全域的角度來看其實很像,只是細節上可能會有所不同。因此採用全域特徵的Transformer可以在UDA的任務中取得較好的預測結果!
2. Rare Class Sampling (RCS)
作者發現使用他們提出來的Transformer架構可以有效地提升困難類別的精準度,但其實這些結果在每次的訓練中都可能有很大的不同,精准度有時候很低(如圖一的藍色曲線)。後來經過實驗發現,如果比較晚才開始訓練困難類別的話,在訓練結束時也容易對應到較低的精準度。作者猜測這有可能是因為不同的Random seed下,我們第一次採樣到困難類別樣本的時間會有很大的變化。若太晚採樣到這些樣本的話,會導致模型在一開始已經專注於學習簡單樣本,此時權重已經被更新成適合預測簡單類別樣本,因此很難再讓他好好地繼續學習困難類別樣本。
🤓 :之前剛開始學DL時,我有做過一個實驗:訓練一個AutoEncoder,讓模型想辦法還原輸入的樣子,之後再使用這個模型作為預訓練權重來訓練語意式分割模型。結果發現,在訓練的一開始,模型會花很多時間來從AutoEncoder的任務變成語意式分割的任務,效果不如直接隨機初始化權重好。
從這個實驗也可以了解到:當模型已經被學習成用於某種任務,此時如果兩種任務差別較大的話,此權重就會很難被更新並應用於其他任務。這或許可以說明作者在這段發現的問題~
(現在聽起來可能有點笨,相差那麼多的任務的權重當然差很多,那時候竟然想拿它來當Pretrained model😂)
為了解決此問題,作者提出了RCS,增加採樣到困難樣本的機率。首先論文中使用式子(6)定義各個類別樣本出現的頻率,之後使用式子(7)的Temperature softmax,讓出現頻率較低的類別對應到較高的抽樣機率P(c)。


下圖為其實驗結果。我們可以發現加入RCS後確實可以有效提升困難類別的IoU,而且其結果也穩定許多!

3. Thing-Class ImageNet Feature Distance (FD)
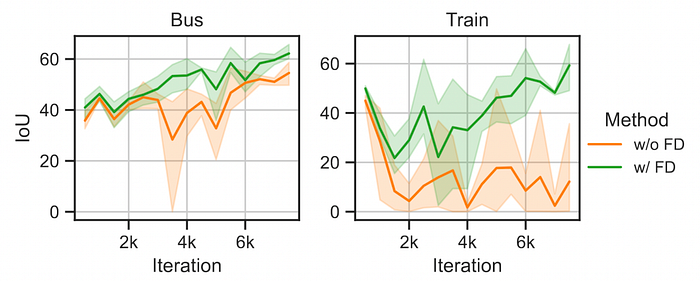
作者發現使用訓練於ImageNet-1k的Pretrain weight來初始化GTA5 ➔ Cityscapes的訓練,Train、Bus兩個類別在一開始還能在目標域上得到還可以的結果。但隨著訓練的時間增加,這些類別的準確度反而會下降。他猜測這可能是因為模型已經Overfit在來源域的Train、Bus,若兩個Domain的這些類別長得不像,則訓練反而會導致模型在目標域無法對這些類別做出良好的預測。
為了改善以上問題,作者提出了FD,讓模型在訓練的過程中仍能提取出與ImageNet pretrained weight相似的特徵,避免發生Overfitting。但因為ImageNet-1k只包含Thing classes,論文中的FD只會套用在這些類別上。
講解完概念,接下來解釋式子!
首先使用式子(8)來計算「當前從模型提取出的特徵」與「使用ImageNet pretrained weight提取出的特徵」的L2 distance。並在式子(9)定義FD的損失函數,當我們最小化這個函數,即維持了模型與ImageNet pretrained weight的相似性。而式子(9)中的M定義於式子(10)中,他是一個Binary mask,用來表示樣本是否屬於Thing class(等於1代表樣本對應到Thing class)。有了這個Mask後,就可以將FD限定於Thing class。
🤓:式子 (10)中的y是一個解析度跟Feature map相同的Label。由於Feature map的解析度會比較小,一個點會對應到輸入照片的一個區塊,因此他會區域性地看一整個區塊中Thing classes所佔的比例,如果比例高於一個閾值,則式子中的M才會等於1。



下圖為論文的實驗結果,可以發現如果沒有FD,Train的IoU確實會隨著訓練而下降。相較之下,加入FD後就可以讓這些類別的IoU隨著訓練而增加。
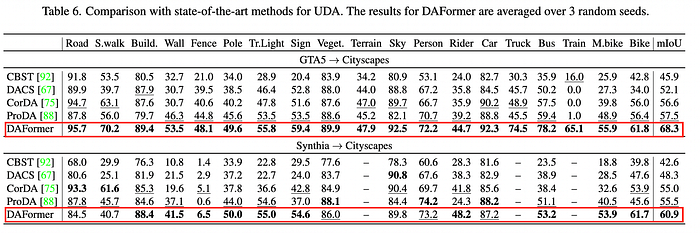
比較DAFormer與過去SOTA方法
論文中使用了GTA5 ➔ Cityscapes與Synthia ➔ Cityscapes兩個Benchmark來比較DAFormer與過去SOTA方法的mIoU。透過下表可以發現,在兩個任務中都有很大的提升,尤其是GTA5 ➔ Cityscapes中的Train直接從16.0提升到65.1!
結語
今天的介紹就到這邊啦,希望可以幫助到大家,如果有幫到你的話也可以幫我點一下喜歡喔!
(內文出自於自己的理解,如果有問題的話歡迎大家一起討論~)
