[論文筆記] HRDA: Context-Aware High-Resolution Domain-Adaptive Semantic Segmentation
論文資訊
前言
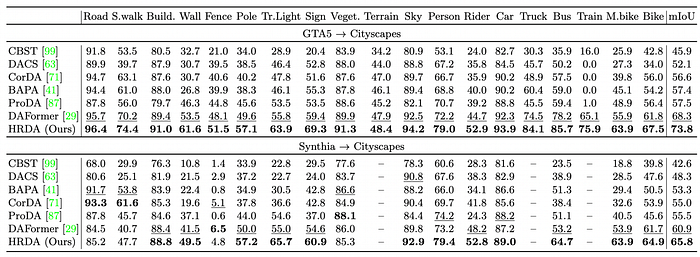
今天要分享的也是UDA領域中,個人認為很重要的一篇論文 —Lukas Hoyer發表於ECCV 2022的HRDA。這篇論文提出的概念大幅地將前一篇SOTA論文DAFormer的mIoU從68.3%提升到73.8%,並且經過筆者實驗,論文中的數據都可以用論文中提供的GitHub重現出來!
如果要用一句話來總結這篇論文,就是在UDA方法中另外加入High-resolution crop,最後再將高、低解析度的預測結果做Fusion。或許有人會想說:「加入High-resolution crop當然會讓準確度提升囉,大家不是都知道嗎」。我一開始也這樣想過,但跟DAFormer一樣,讀完論文就能理解到作者的思路並沒有那麼單純,而是很巧妙地將這個技巧與UDA的特性結合!至於具體怎麼做就繼續看下去吧~
摘要
UDA演算法中,往往需要使用額外的Components來訓練,在GPU大小受限的情況下,我們很難使用原解析度的資料來訓練模型。為了解決這個問題,過去的方法通常都會在訓練的時候先把資料下採樣。不過下採樣會導致小物體的特徵遺失,讓我們很難對他們做出良好的預測。為了解決這個問題,有的方法也會採用Random crop的方式隨機選擇其中的一小區域的圖,藉由此方式來避免影像的下採樣,保留原圖的細節特徵。
有些類別的物體本身就很大,即使將影像下採樣,還是可以很好地做出正確預測。此時由於兩個Domain具備不同的特徵,如果對大型物體採用Random crop,反而會造成模型Overfit在來源域限定的細節特徵,進而導致Domain shift problem加劇;有些類別的物體面積較小,如果將其下採樣則會造成特徵遺失。基於這個分析,我們可以知道UDA中,有些樣本應該採用高解析度,有些則應該採用低解析度的預測結果。
為了實現以上想法,論文中提出一種同時運高、低解析度特徵的方法:HRDA。此方法在運作時會得到 (1) Context crop(大範圍低解析度)、(2) Detail crop(小範圍高解析度),之後將這兩個Crop分別丟入模型得到兩個預測結果,最後再將兩個預測結果Fuse成最終預測結果。這邊的Fusion採用了Attention module,來看各個樣本點較需要哪種特徵。

論文提出的方法
HRDA架構中的Attention module
如下圖,架構中的Attention decoder跟Semantic decoder平行,他們會使用同一個Feature encoder提取到的特徵。此Decoder的輸出結果會經過Sigmoid得到Attention map,因此其輸出結果會介於0、1。之後在做Fusion時,如果Attention score:
- 越接近1:多Fuse一點Detail crop的預測結果。
- 越接近0:多Fuse一點Contect crop的預測結果。

如何取得兩個不同Crop?
使用以下方式取得兩個不同的Crop後,我們就可以使用相同的模型來得到兩者的預測結果,因為兩種Crop的解析度會相同。
- 從原圖中隨機取一個較大的Crop,這邊為了方便説明先叫他C。
- 使用C分別得到兩種不同的Crop:
- Context crop: 直接將C以Bilinear的方式做下採樣。
- Detail crop: 從C中隨機Crop出一個更小的區塊。
🤓:最後Context crop跟Detail crop會具備相同的解析度!
如何實現HRDA中的Fusion?
HRDA使用Attention map來將高、低解析度的預測結果做Fusion。為了完整介紹整個流程,我會將此部分分成以下兩個部分依序介紹~
- 取得Attention map的方式。
- 如何透過Attention map來做Fusion。
那就開始吧!
1. 取得Attention map的方式
作者在論文中提到,Context crop保留較多原圖的Layout information,因此Attention module採用從Context crop提取的特徵作為輸入。但由於Detail crop並不包含所有Context crop的樣本點,因此Fusion時,這些部分會直接採用Context crop的預測結果,也就是直接將這些地方的Attention score設定為0!(如圖三中的Attention map)
2. 如何透過Attention map來做Fusion?
如式 (12),最後在做Fusion時,我們會先將兩個Crop的預測結果上採樣到原始解析度,再將其結果相加。
- 式子中的左半邊與Context crop相關:由於Attention map是使用Context crop得到的,他會具備跟Context crop預測結果相同的解析度,因此可以直接點對點相乘,最後再透過ζ(.)上採樣回原解析度。
- 式子中的右半邊與Detail crop相關:由於Detail crop與Attention map無法直接對應,因此需要先分別以不同的方式上採樣回原解析度,之後再點對點相乘。Detail crop的上採樣方式如式 (11),不使用插值的方式放大,而是將Detail crop放回他原本在原圖的位置,而本來原圖中沒有被Crop到的部分則補零取代(如圖三中的Inserted detail crop)。
待兩邊都分別上採樣至原解析度,也與Attention map相乘後,再來就只要把兩個部分加再一起就完成Fusion了!
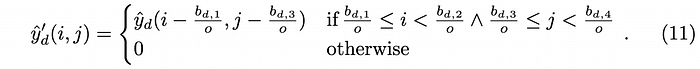
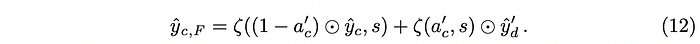
🙋🏻♂️:式 (12)中的ζ(.)為用來做上採樣的Operator;⊙則是點對點相乘的Operator。

Loss Functions
HRDA的損失函數採用標準的Cross Entropy Loss。雖然Fusion後的結果本身就包含Detail crop的資訊,但作者說如果在損失函數中加入Detail crop的Term,可以讓模型學到更穩健的高解析度特徵。因此不論是來源域還是目標域,都包含Fused prediction(左半邊)、Detail crop的預測結果(右半邊)。
🙋🏻♂️:式 (13)、式 (14)中的p代表Pseudo-labels,q則代表Pseudo-labels的Confidence。
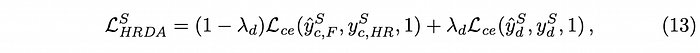

🤓:我認為目標函數之所以要包含Detail term的原因是:Fusion時,Detail crop在大物體的權重不會真的等於0,而是由Attention score決定的近似0的數值。因此加上那個Term讓Detail crop具備預測大物體的能力,可以讓效果變好。(如果理解有錯歡迎大家討論指教~)
使用Sliding window的方式得到目標域Pseudo-labels
前面說過,訓練的Prediction並不是每個點都有考慮Detail crop的資訊,但我們希望Pseudo-labels不論在哪個部分都應該要有很高的品質,因此會希望每部分都可以同時考慮到Context、Detail information,之後再Fusion。因此,在取得Pseudo-labels時,我們需要得到每個部分的Detail crop。
雖然取得Pseudo-labels的過程不包含反向轉播,不會有記憶體不夠的問題,我們其實是可以直接將原圖丟入模型取得所有像素點的Detail Prediction。但HRDA是基於DAFormer架構修改的,使用了Transformer架構,他在訓練時會隱性地學到Positional embedding,這種時候Inference要使用跟Training相同的輸入解析度,才能得到較好的結果。基於這個原因,為了不讓準確度下降,我們會改成使用跟前面講到相同的解析度來取得各塊的Detail crop。其中我們會以Sliding window的方式來取得Detail crops,並將各個重疊部分的預測結果取平均,取得更穩健的Pseudo-labels。
🤓:為什麼只有Pseudo-labels要考慮所有像素點的Detail information,而訓練時的Prediction不用呢?
我覺得只要Pseudo-labels是準的就好了。因為即使有些像素點只有對應到Context crop,沒有Detail crop,也可以變成是讓Context crop也具備預測小物體的能力。雖然Context crop預測小物體的能力不如Detail crop,但這樣做其實對整體還是有益的。原因是Fusion時,Context crop在小物體的權重不會真的變成0,這時如果Context crop也具備預測小物體的能力,對整體結果反而會是好的!(如果理解有錯歡迎大家討論指教~)🤓:我們可能會覺得Sliding window很慢,但其實論文中提到:我們可以將所有Windows對應到的Crop組成一個Batch的資料,平行地取得他們的預測結果。因此在使用GPU時,運算速度並不會特別慢!
實驗結果
可以看到LR、HR的預測結果確實如論文一開始說的一樣,而且Attention map也能有效地找出正確的大小物體,最後使用這個東西來Fuse兩個結果,可以讓最終結果結合兩者的優點!

結語
今天的介紹就到這邊啦,希望可以幫助到大家,如果有幫到你的話也可以幫我點一下Clap或追蹤我的Medium喔!
(內文出自於自己的理解,如果有問題的話歡迎大家一起討論~)
